So, with a 6-drive RAIDZ2, I faced a drive failure over a year ago with a “hung” Windows host (hosting the Ubuntu Server LTS Hyper-V VM with pass-through, direct access to the 6 physical HDDs used for the RAIDZ2 array) – the Windows UI was still responsive but any drive reads (e.g. Windows Explorer navigation, starting an app) “hung” the offending app attempting the drive reads (even if the dying drive was not the drive being read from)… With 2x 6TB “spares” on hand purchased over time (2017, 2018) for just such an event, a VM-and-host shutdown, HDD swap and a quick zfs replace <pool> <old GUID> <new /dev/sdx> and a “quick” resilver brought everything back to normal.
Then, three months back, I then started facing 2 failed drives – I had the one remaining 6TB “spare” replacement drive for the first, but after a 2nd failure in the span of these three months (without purchasing another set of standby replacements), it was time to start considering replacing all the drives (slowly).
Not too shabby, with ~7+ years’ lifespan of near 24/7 powered-on, low-drive write loads, with some pretty bad temperatures (near constant 50°+C to 60°C, no matter how I tried to force air flow when these were still in the DS380):
- 2x Seagate ST6000DX001:
- from March 2015
- 1x failed in August 2016; RMA/replacement still running
- 2x Seagate ST6000DM001:
- from November 2015
- 1x failed in November 2022
- 1x failed in November 2023
- 4x Toshiba X300 HDWE160:
- 2x from July 2016
- 1x from November 2017 (spare)
- 1x (surprisingly the replacement drive from November 2017 that was “just” plugged in in November 2022) (just) failed in February 2024
- 1x from November 2018 (spare)

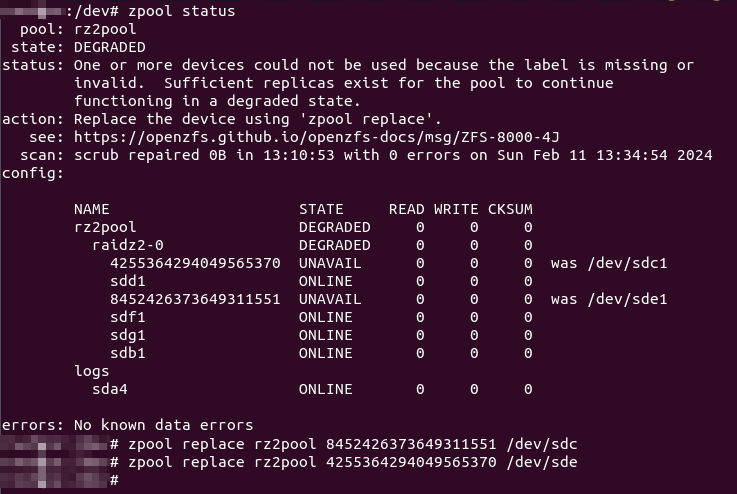
I therefore purchased 2x Seagate Exos X18 16TB HDDs, with another still on the way… Wanting to minimise the number of resilver attempts (straining the surviving 6TBs), I attempted to pull a working drive from the degraded 5-drive RAIDZ2 array and plugged both new 16TBs in, fingers crossed that none of the remaining 4 drives give up the ghost while resilvering (confident I had important data backed up elsewhere).
I gave the replacement commands one after another:
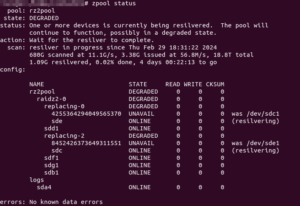
2024/03/03 Update: Don’t assign the whole disk, manually create a partition instead and assign that as replacement instead!
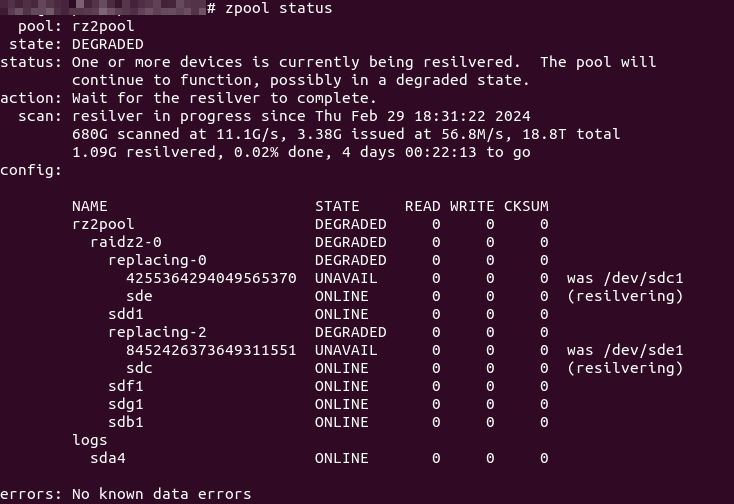
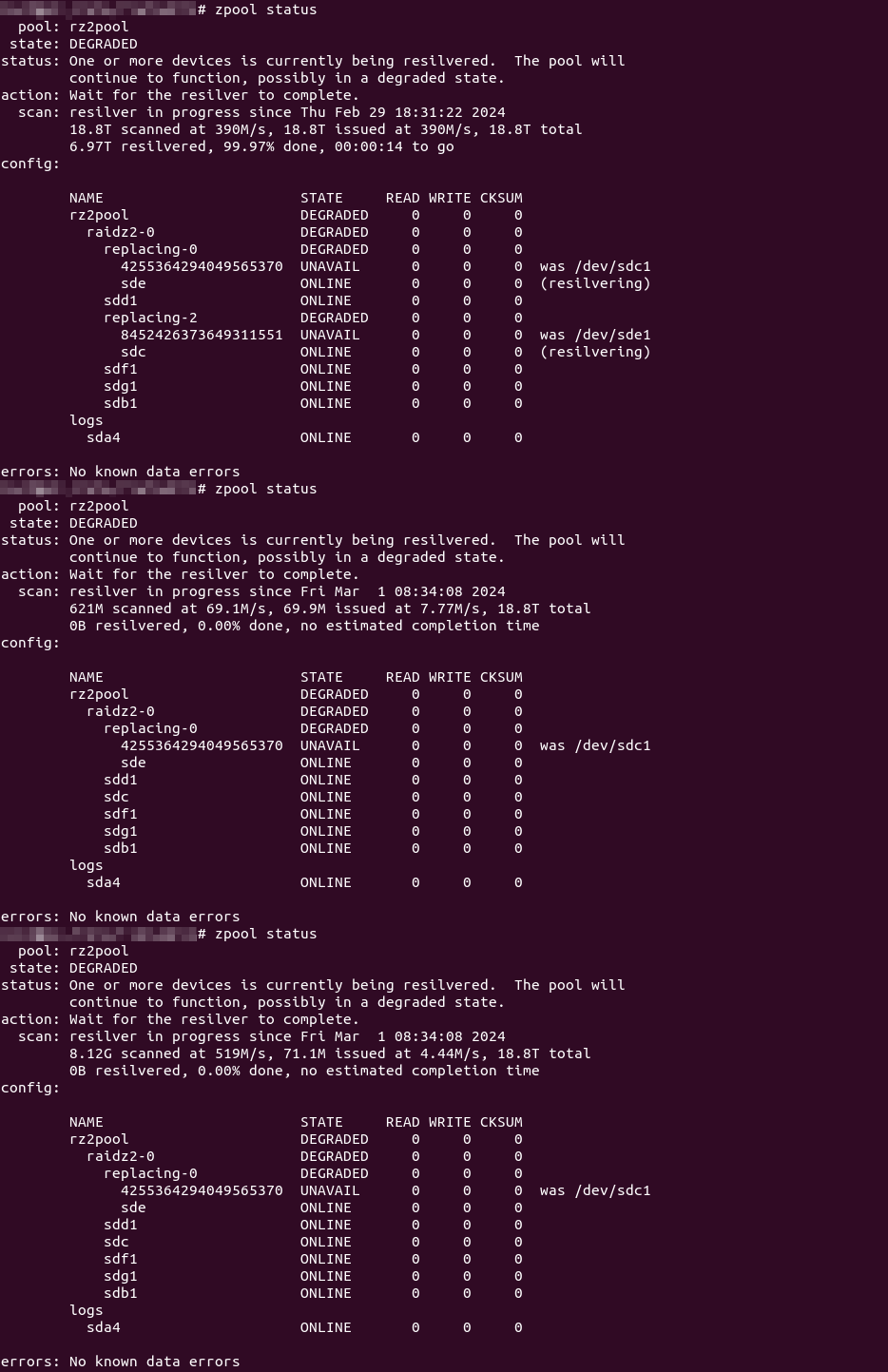
And that seems to work… So, 11+ hours later, nearing the end of the resilver process, I was eagerly checking the status…
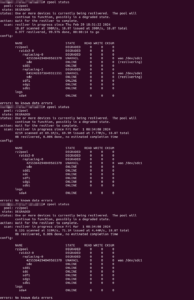
Wha..?!? Resilvering only completed on one drive (and was only now starting on the other)!
Continue reading →