Finally, we start installing the ZFS packages and start the RAIDZ2 set-up (no screenshot):
apt-get zfsutils-linux
For several reasons, I chose to use:
- vdevs created “by-id”:
- as per advice from multiple places online, using the “easier”
/dev/sdxidentifier may break things should the order be changed (e.g. you swapped cable ends or drive cages, etc.)
- as per advice from multiple places online, using the “easier”
- lz4 compression
- as per statistics from some places, the “cost” of LZ4 is relatively low/negligible
Building the RAIDZ2 zpool
To prevent errors (and use “copy-paste”), first list the partitions “by ID”, then create the RAIDZ2 vdev and zpool at the same time:
ls -l /dev/disk/by-partlabel ls -l /dev/disk/by-id zpool create -o ashift=12 <pool name> raidz2 /dev/disk/by-id/<partition IDs> zdb | grep ashift
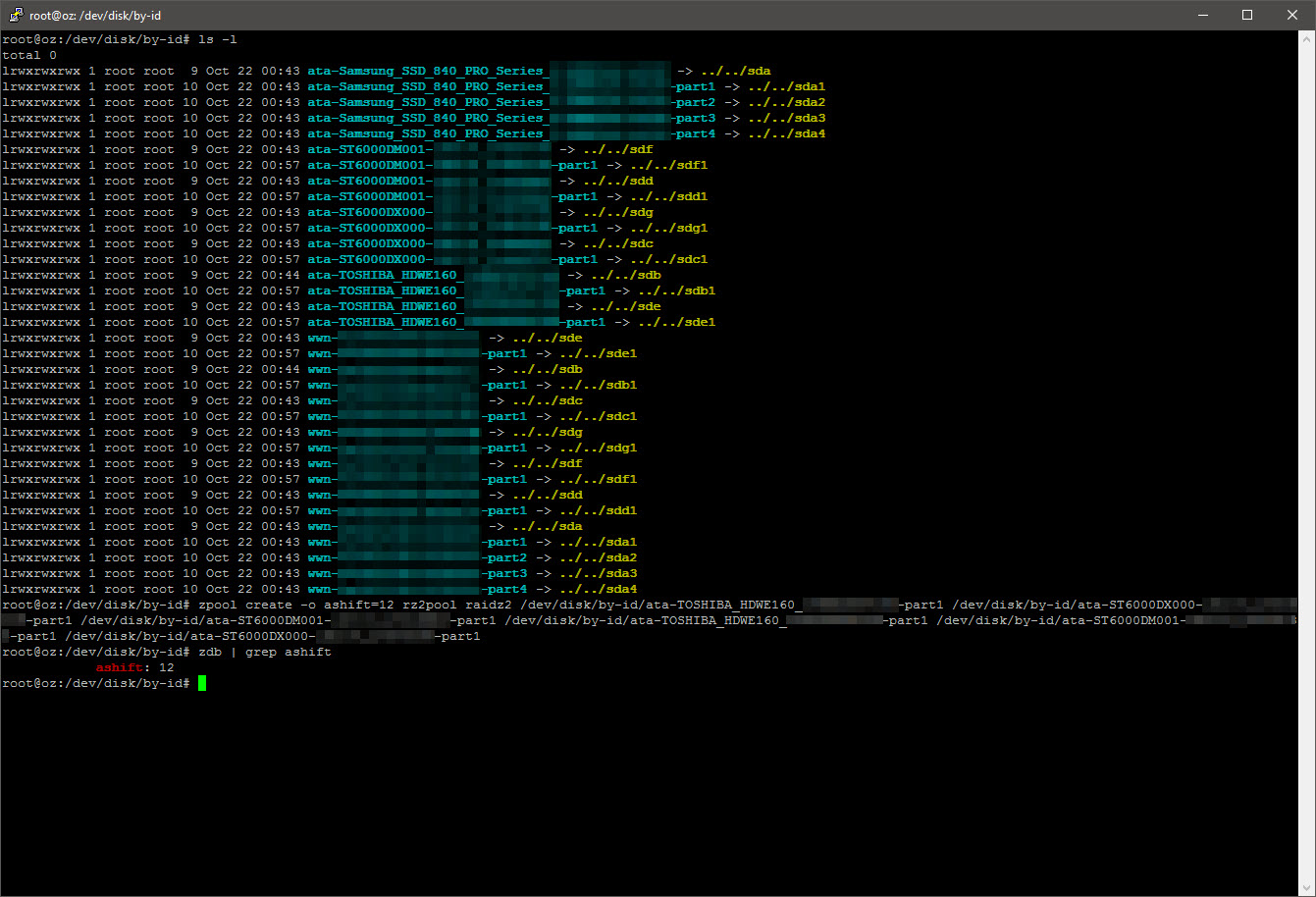
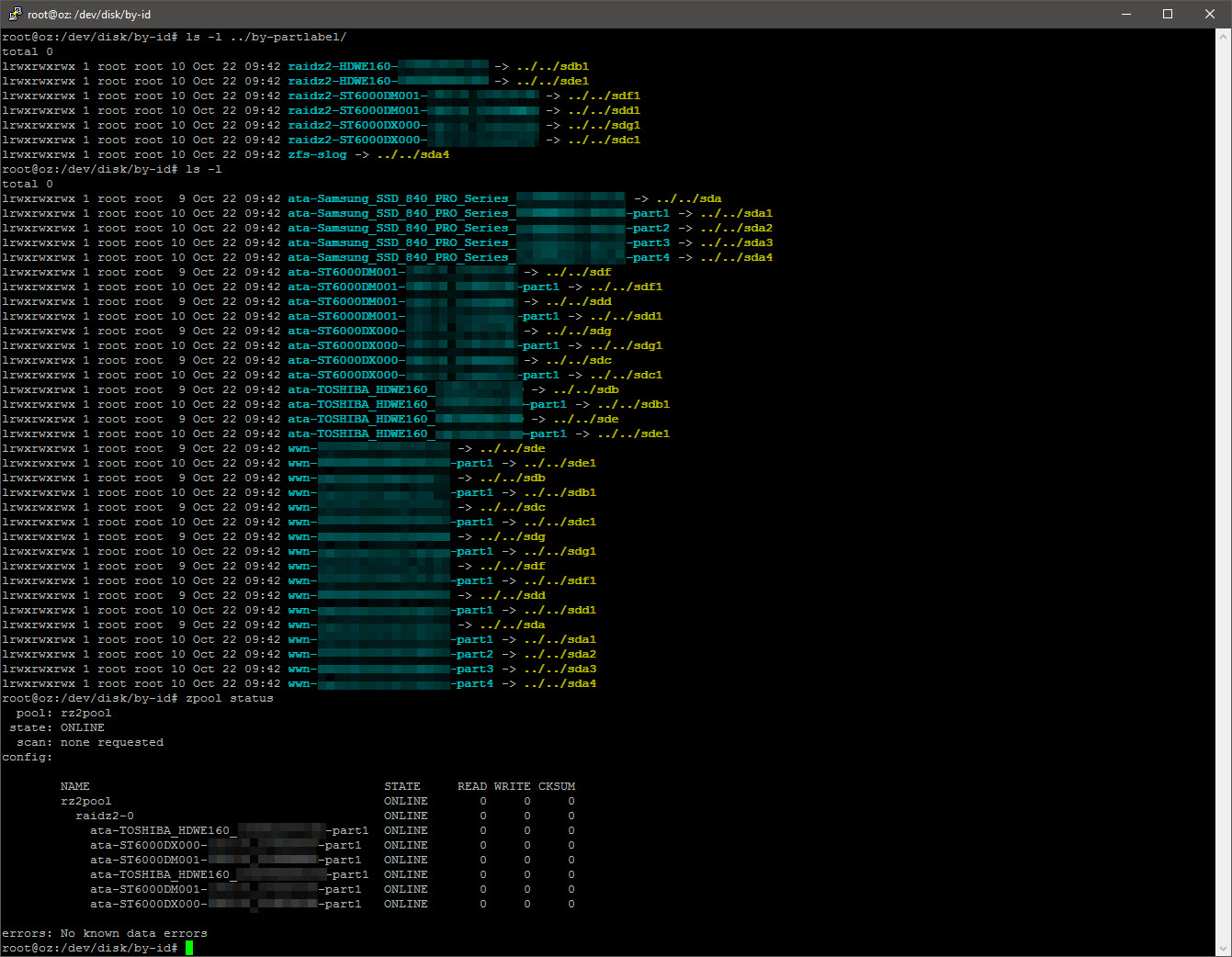
zfs set compression=lz4 <pool name> zfs mount
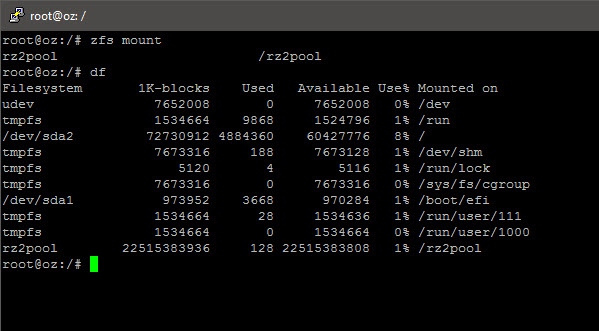
Adding the SLOG
So, the zpool is now created. Now, to assign the pre-built raw/unformatted partition on the SSD as the SLOG, then force synchronous writes (as the penalty for such is much less with the fast SSD-based SLOG vs. pool-based ZIL and I do not wish to lose data):
zpool add <pool name> log /dev/by-id/<partition ID>zfs set sync=always <pool name>
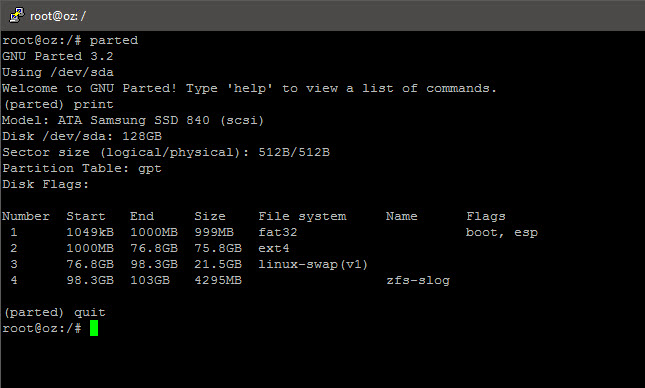
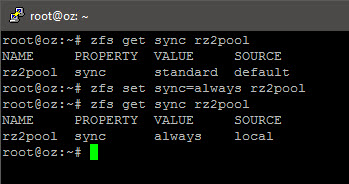
2016/10/23 Update: Performance crawled (dips to 30-90MB/s on local interface copy) after forcing sync writes, despite the SSD-based SLOG; possibly no resolution unless the SLOG sits on a near-RAM-performance interface+drive and is striped. I have reversed the change, i.e. run
zfs set sync=standard <pool name>
Done!
Now, everything is done!
zpool status
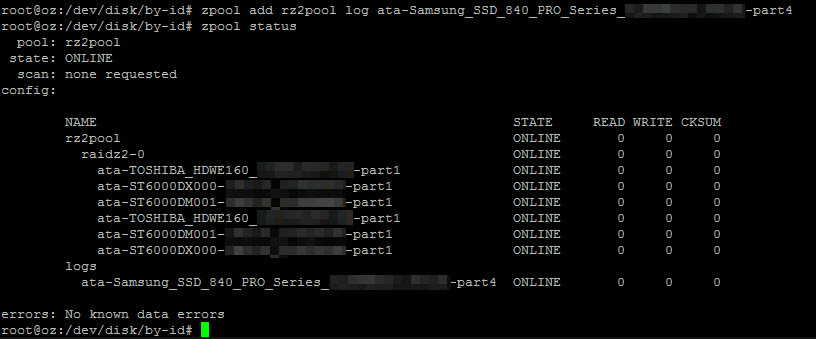
You could, if you wanted, start creating ZFS datasets, such that different options (e.g. dittoblocks, compression, quotas) may be set at the dataset level.
zfs create <pool name>|<dataset name>
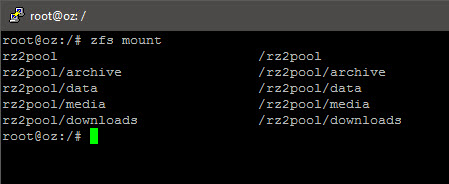
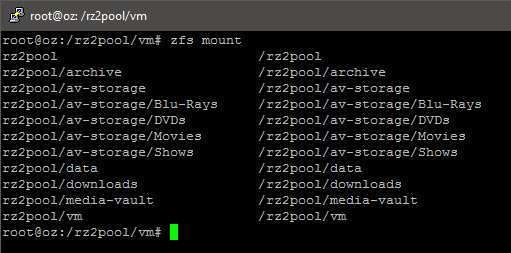
2016/10/24 Update: Due to the fact that performance may degrade over time, and that the only fix (known as of writing this) is to literally move the dataset off-system, delete and move it back, I decided to further “break down” my datasets into nested ones:
zfs create rz2pool/<parent> zfs create rz2pool/<parent>/<child>
I would advise you to plan carefully before deployment as you will not be able to “re-assign”/change a “sub-directory” to become a separate dataset. i.e. You will have to move the data over to a newly created (nested) dataset.
I have started copying stuff from the backup HDD plugged directly into the “spare” cage slot on my DS380…
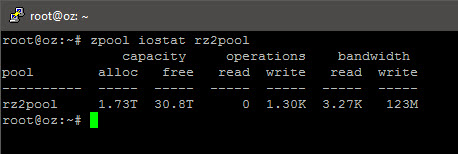
Throughput of 120+ MB/s from the single 3TB source to the RAIDZ2 pool seems “OK”…
Next step: creating the shares…
